LeNet
论文地址Gradient based learning applied to document recognition
该网络主要用于手写数字识别,基本框架都有,包括卷积、激活、池化和全连接。结构图如下:
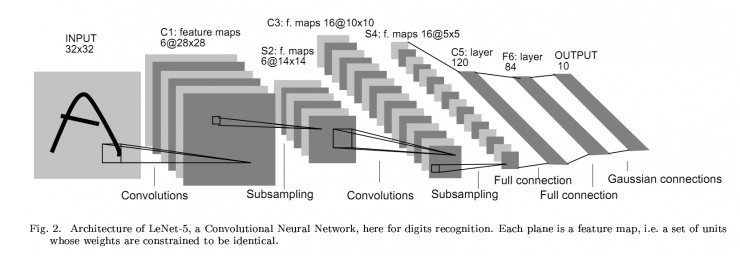
PS: 一个很好的LeNet可视化项目:LeNet-5可视化
AlexNet
论文地址ImageNet Classification with Deep Convolutional Neural Networks
网络结构如下所示:
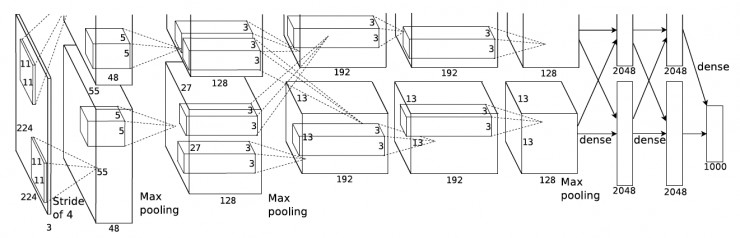
该网络总体结构和LeNet相似,但是有极大改进:
- 由五层卷积和三层全连接组成,输入图像为三通道224*224大小,网络规模远大于LeNet
- 使用了ReLU激活函数
- 使用了Dropout,可以作为正则项防止过拟合,提升模型鲁棒性
- 一些比较好的训练技巧,包括数据增广、学习率策略、weight decay等。
VGG
论文地址Very deep convolutional networks for large-scale image recognition
网络结构如下所示:
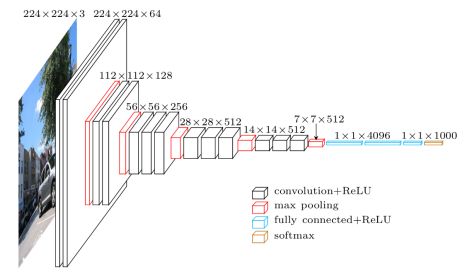
VGGNet中采用了小卷积核,直观上我们会认为大的卷积核会更好,因为它可以提取到更大区域内的信息,实际上,大卷积核可以用多个小卷积核代替。例如,一个55的卷积可以用两个串联的33卷积代替。这种替代方式有两点好处:
-
减少参数个数:
两个串联的小卷积核需要332=18个参数,一个55的卷积核则有25个参数。 三个串联的小卷积核需要333=27个参数,一个77的卷积核则有49个参数。
-
引入了更多的非线性:
每一个小卷积核对应着一个激活过程。引入更多的非线性变换,也就意味着模型的表达能力更强,可以去拟合更高维的分布。
Inception v1(GoogleNet)
论文地址Going deeper with convolutions
网络结构如下所示:
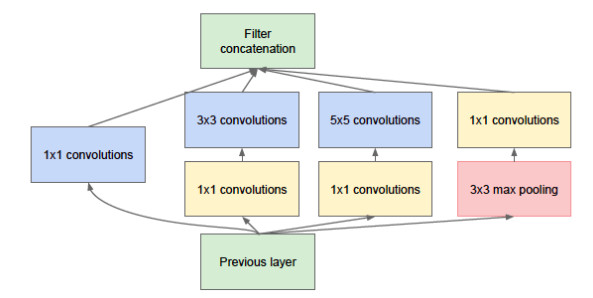
GoogleNet的核心思想是将全连接,甚至是卷积中的局部连接,全部替换成稀疏连接。
- 生物神经系统中的连接是稀疏的;
- 如果一个数据集的概率分布可以由一个很大、很稀疏的深度神经网络网络表示时,那么分析最后一层激活值的相关统计和对输出高度相关的神经元的神经元进行聚类,可以逐层地构建出一个最优网络拓扑结构。另外研究表明,可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能。
ResNet
论文地址Deep residual learning for image recognition
网络结构如下所示:
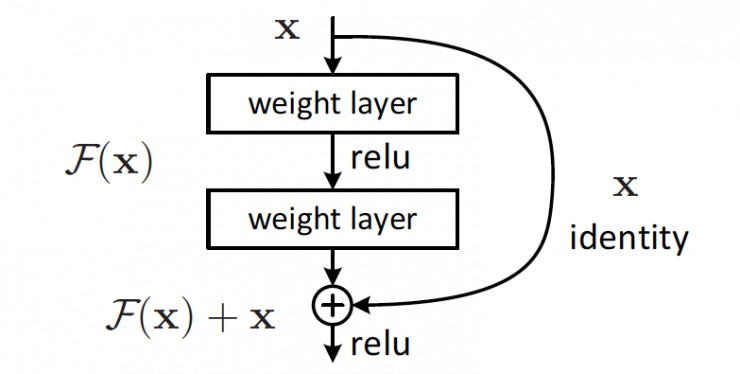
ResNet通过引入shortcut直连的方式来解决网络太深无法很好训练的问题。通过引入直连,原来需要学习完全的重构映射,现在只需要学习输出和原来输入之间的差值即可,绝对量变成了相对量,因此叫做残差网络。
如果说LeNet、AlexNet、VGG奠定了经典神经网络的基础,Inception和ResNet则展示了神经网络的新范式,在这两个范式的基础上,发展创新并相互借鉴,有了Inception流派的Inception v2到v4、Inception-ResNet v1和v2,以及ResNet流派的ResNeXt、DenseNet和Xception等。
Inception流派
Inception v2(BN-Inception)
论文地址Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
该网络主要增加了Batch Normalization。网络的每一层输出后面加上归一化变换,减去每个训练batch的每个特征的均值再除以标准差,得到均值0标准差1的输出分布,有助于训练。
Inception v3
论文地址Rethinking the Inception Architecture for Computer Vision
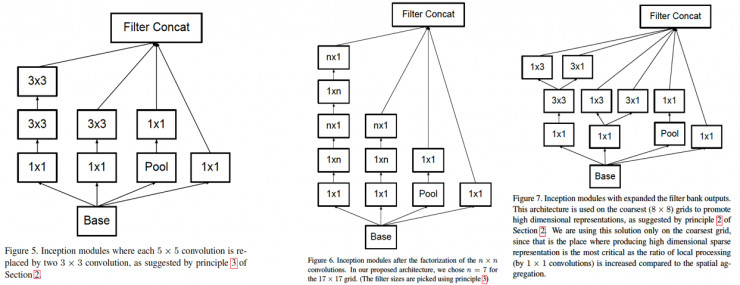
该卷积进一步分解,55用两个33卷积替换,77用三个33卷积替换,一个33卷积核可以进一步用13的卷积核和3*1的卷积核组合来替换,进一步减少计算量。网络结构如下所示:
Inception v4、Inception-ResNet v1和v2
论文地址Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
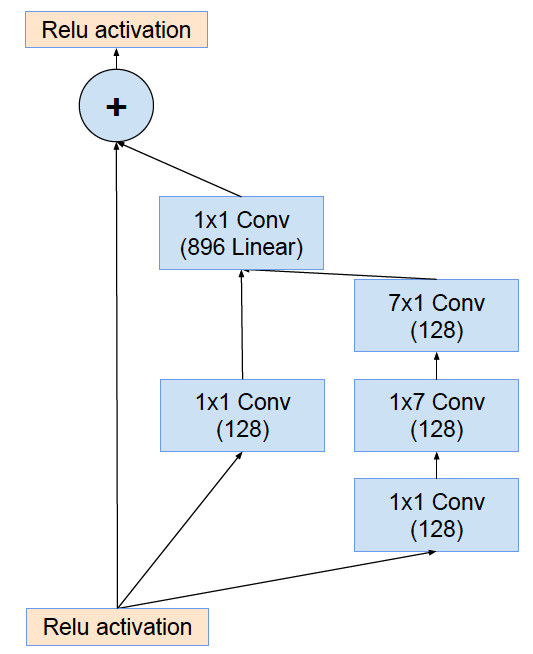
同时,ResNet的成功,说明了residual connection的有效性,为了Inception模块引入了residual connection,得到Inception-ResNet-v1和Inception-ResNet-v2,前者规模较小,和Inception v3相当,后者规模和Inception v4相当。Residual结构的Inception模块的结构如下:
ResNet流派
ResNet是另一个主流分支,包括DenseNet,ResNeXt以及Xception等。
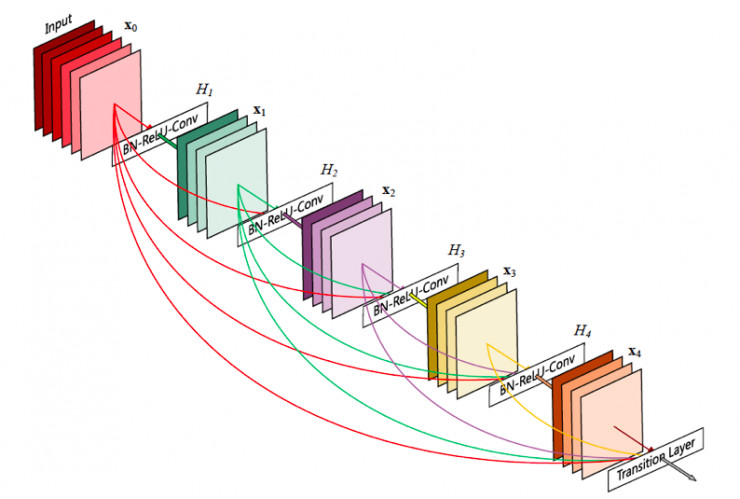
DenseNet
论文地址Densely Connected Convolutional Networks
DenseNet将residual connection发挥到极致,每一层输出都直连到后面的所有层,可以很好地复用特征。缺点是显存占用更大并且反向传播计算更复杂一点。网络结构如下:
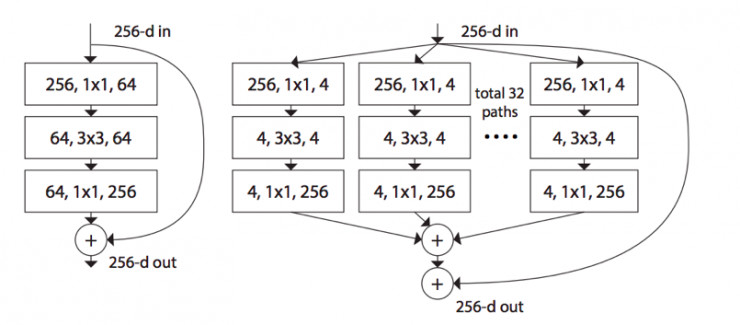
ResNeXt
论文地址Aggregated Residual Transformations for Deep Neural Networks
Inception借鉴ResNet得到Inception-ResNet,而ResNet借鉴Inception得到ResNeXt,对于一个ResNet的每一个基本单元,横向扩展,将输入分为几组,使用相同的卷积,进行卷积。网络结构如下:
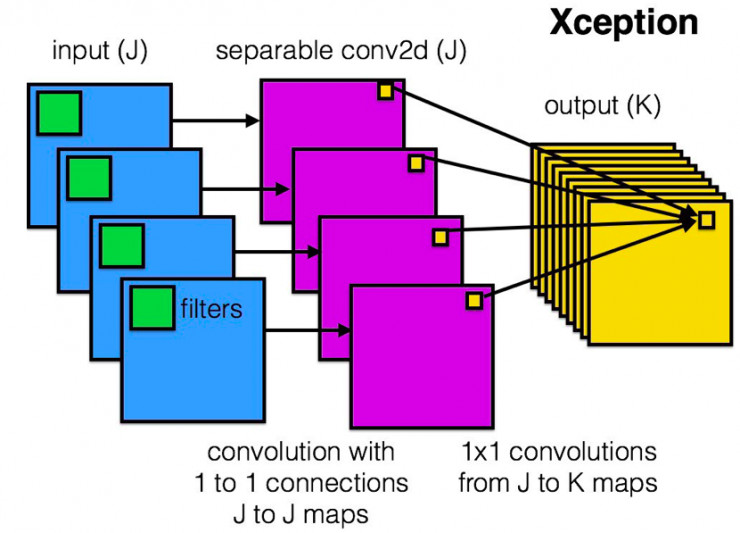
Xception
论文地址Xception: Deep Learning with Depthwise Separable Convolutions
Xception是把分组卷积的思想发挥到了极致,每一个通道单独分为一组。网络结构如下所示:
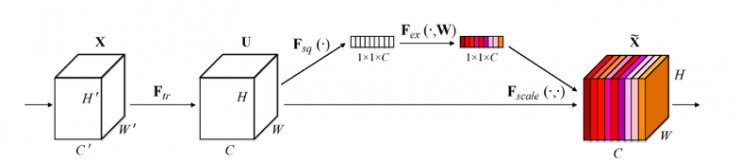
SENet
最近又出现了一些新的网络,比如NASNet,SENet,MSDNet等。具体可以参见Pytorch的pretrainedmodel。
其中SENet的Squeeze-Excitation 模块在普通的卷积(单层卷积或复合卷积)由输入 X 得到输出 U 以后,对 U 的每个通道进行全局平均池化得到通道描述子(Squeeze),再利用两层 FC 得到每个通道的权重值,对 U 按通道进行重新加权得到最终输出(Excitation),这个过程称之为 feature recalibration,通过引入 attention 重新加权,可以得到抑制无效特征,提升有效特征的权重,并很容易地和现有网络结合,提升现有网络性能,而计算量不会增加太多。具体网络结构如下:
总结
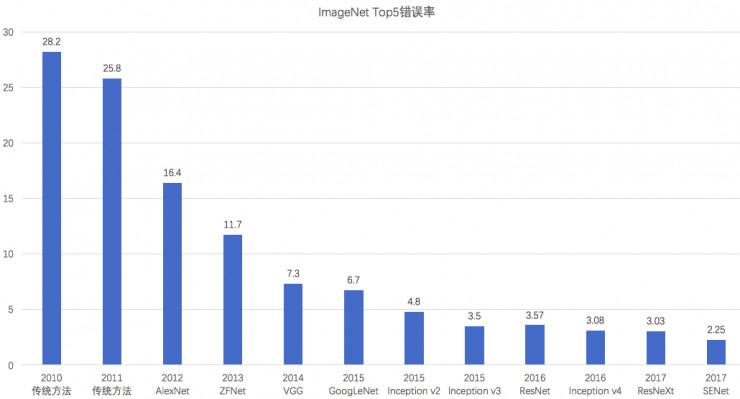
最后给出一个在ImageNet的Top5准确率,如下图所示: